TensorFlow损失函数的示例分析-创新互联
这篇文章将为大家详细讲解有关TensorFlow损失函数的示例分析,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
让客户满意是我们工作的目标,不断超越客户的期望值来自于我们对这个行业的热爱。我们立志把好的技术通过有效、简单的方式提供给客户,将通过不懈努力成为客户在信息化领域值得信任、有价值的长期合作伙伴,公司提供的服务项目有:国际域名空间、虚拟主机、营销软件、网站建设、万州网站维护、网站推广。一、分类问题损失函数——交叉熵(crossentropy)
交叉熵刻画了两个概率分布之间的距离,是分类问题中使用广泛的损失函数。给定两个概率分布p和q,交叉熵刻画的是两个概率分布之间的距离:
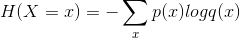
我们可以通过Softmax回归将神经网络前向传播得到的结果变成交叉熵要求的概率分布得分。在TensorFlow中,Softmax回归的参数被去掉了,只是一个额外的处理层,将神经网络的输出变成一个概率分布。
代码实现:
import tensorflow as tf
y_ = tf.constant([[1.0, 0, 0]]) # 正确标签
y1 = tf.constant([[0.9, 0.06, 0.04]]) # 预测结果1
y2 = tf.constant([[0.5, 0.3, 0.2]]) # 预测结果2
# 以下为未经过Softmax处理的类别得分
y3 = tf.constant([[10.0, 3.0, 2.0]])
y4 = tf.constant([[5.0, 3.0, 1.0]])
# 自定义交叉熵
cross_entropy1 = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y1, 1e-10, 1.0)))
cross_entropy2 = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y2, 1e-10, 1.0)))
# TensorFlow提供的集成交叉熵
# 注:该操作应该施加在未经过Softmax处理的logits上,否则会产生错误结果
# labels为期望输出,且必须采用labels=y_, logits=y的形式将参数传入
cross_entropy_v2_1 = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y3)
cross_entropy_v2_2 = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y4)
sess = tf.InteractiveSession()
print('[[0.9, 0.06, 0.04]]:', cross_entropy1.eval())
print('[[0.5, 0.3, 0.2]]:', cross_entropy2.eval())
print('v2_1', cross_entropy_v2_1.eval())
print('v2_2',cross_entropy_v2_2.eval())
sess.close()
'''''
[[0.9, 0.06, 0.04]]: 0.0351202
[[0.5, 0.3, 0.2]]: 0.231049
v2_1 [ 0.00124651]
v2_2 [ 0.1429317]
'''tf.clip_by_value()函数可将一个tensor的元素数值限制在指定范围内,这样可防止一些错误运算,起到数值检查作用。
* 乘法操作符是元素之间直接相乘,tensor中是每个元素对应相乘,要去别去tf.matmul()函数的矩阵相乘。
tf.nn.softmax_cross_entropy_with_logits(labels=y_,logits=y)是TensorFlow提供的集成交叉熵函数。该操作应该施加在未经过Softmax处理的logits上,否则会产生错误结果;labels为期望输出,且必须采用labels=y_, logits=y3的形式将参数传入。
二、回归问题损失函数——均方误差(MSE,mean squared error)
均方误差亦可用于分类问题的损失函数,其定义为:
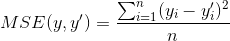
三、自定义损失函数
对于理想的分类问题和回归问题,可采用交叉熵或者MSE损失函数,但是对于一些实际的问题,理想的损失函数可能在表达上不能完全表达损失情况,以至于影响对结果的优化。例如:对于产品销量预测问题,表面上是一个回归问题,可使用MSE损失函数。可实际情况下,当预测值大于实际值时,损失值应是正比于商品成本的函数;当预测值小于实际值,损失值是正比于商品利润的函数,多数情况下商品成本和利润是不对等的。自定义损失函数如下:
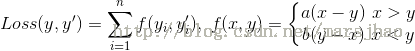
TensorFlow中,通过以下代码实现loss= tf.reduce_sum(tf.where(tf.greater(y, y_), (y-y_)*loss_more,(y_-y)*loss_less))。
tf.greater(x,y),返回x>y的判断结果的bool型tensor,当tensor x, y的维度不一致时,采取广播(broadcasting)机制。
tf.where(condition,x=None, y=None, name=None),根据condition选择x (if true) or y (if false)。
代码实现:
import tensorflow as tf
from numpy.random import RandomState
batch_size = 8
x = tf.placeholder(tf.float32, shape=(None, 2), name='x-input')
y_ = tf.placeholder(tf.float32, shape=(None, 1), name='y-input')
w1 = tf.Variable(tf.random_normal([2,1], stddev=1, seed=1))
y = tf.matmul(x, w1)
# 根据实际情况自定义损失函数
loss_less = 10
loss_more = 1
# tf.select()在1.0以后版本中已删除,tf.where()替代
loss = tf.reduce_sum(tf.where(tf.greater(y, y_),
(y-y_)*loss_more, (y_-y)*loss_less))
train_step = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
rdm = RandomState(seed=1) # 定义一个随机数生成器并设定随机种子
dataset_size = 128
X = rdm.rand(dataset_size, 2)
Y = [[x1 + x2 +rdm.rand()/10.0 - 0.05] for (x1, x2) in X] # 增加一个-0.05~0.05的噪声
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
for i in range(5000):
start = (i * batch_size) % dataset_size
end = min(start+batch_size, dataset_size)
train_step.run({x: X[start: end], y_: Y[start: end]})
if i % 500 == 0:
print('step%d:\n' % i, w1.eval())
print('final w1:\n', w1.eval())
sess.close()
'''''
loss_less = 10
loss_more = 1
final w1:
[[ 1.01934695]
[ 1.04280889]]
loss_less = 1
loss_more = 10
final w1:
[[ 0.95525807]
[ 0.9813394 ]]
loss_less = 1
loss_more = 1
final w1:
[[ 0.9846065 ]
[ 1.01486754]]
'''根据程序输出可见,当我们将loss_less=10时,表明我们对预测值过小表征的损失值更大,优化得到的参数均略大于1;当loss_more=10时,表明我们对预测值过大表征的损失值更大,优化得到的参数均略小于1;当两者均设为1时,得到的参数约等于1。
四、TensorFlow的Cross_Entropy实现
1. tf.nn.softmax_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, dim=-1, name=None)
该函数的功能是自动计算logits(未经过Softmax)与labels之间的cross_entropy交叉熵。
该操作应该施加在未经过Softmax处理的logits上,否则会产生错误结果;labels为期望输出,且必须采用labels=y_,logits=y3的形式将参数传入。
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上。
注意:如果labels的每一行是one-hot表示,也就是只有一个地方为1,其他地方为0,可以使用tf.sparse_softmax_cross_entropy_with_logits()
警告: (1)这个操作的输入logits是未经缩放的,该操作内部会对logits使用softmax操作;(2)参数labels,logits必须有相同的形状 [batch_size, num_classes] 和相同的类型(float16, float32,float64)中的一种。
该函数具体的执行过程分两步:首先对logits做一个Softmax,
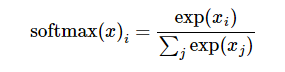
第二步就是将第一步的输出与样本的实际标签labels做一个交叉熵。
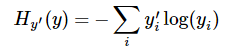
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到交叉熵,如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
2. tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
该函数与tf.nn.softmax_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, dim=-1, name=None)十分相似,唯一的区别在于labels,该函数的标签labels要求是排他性的即只有一个正确类别,labels的形状要求是[batch_size] 而值必须是从0开始编码的int32或int64,而且值范围是[0, num_class),对比于tf.nn.softmax_cross_entropy_with_logits的[batchsize,num_classes]格式的得分编码。
其他使用注意事项参见tf.nn.softmax_cross_entropy_with_logits的说明。
3. tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
sigmoid_cross_entropy_with_logits是TensorFlow最早实现的交叉熵算法。这个函数的输入是logits和labels,logits就是神经网络模型中的 W * X矩阵,注意不需要经过sigmoid,而labels的shape和logits相同,就是正确的标签值,例如这个模型一次要判断100张图是否包含10种动物,这两个输入的shape都是[100, 10]。注释中还提到这10个分类之间是独立的、不要求是互斥,这种问题我们称为多目标(多标签)分类,例如判断图片中是否包含10种动物中的一种或几种,标签值可以包含多个1或0个1。
4. tf.nn.weighted_cross_entropy_with_logits(targets, logits, pos_weight, name=None)
weighted_sigmoid_cross_entropy_with_logits是sigmoid_cross_entropy_with_logits的拓展版,多支持一个pos_weight参数,在传统基于sigmoid的交叉熵算法上,正样本算出的值乘以某个系数。
关于“TensorFlow损失函数的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
网页标题:TensorFlow损失函数的示例分析-创新互联
网页地址:https://www.cdcxhl.com/article12/csgedc.html
成都网站建设公司_创新互联,为您提供云服务器、网站设计、企业建站、移动网站建设、网站改版、外贸建站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 做SEO时网站收录不稳定或是不收录怎么办? 2022-09-14
- 影响搜索引擎收录网站速度的原因有哪些 2016-11-04
- 提高网站收录率请从建站开始! 2021-04-11
- 影响网站收录的主要因素 2017-02-27
- 网站的收录和虚拟主机有关系吗? 2016-10-22
- 增加网站收录的四大秘诀! 2022-12-15
- 网站收录量与索引量不一样的原因 2013-05-18
- 老网站长时间文章没收录应该怎么办? 2014-10-16
- 短期内快速增加网站收录量的方法 2016-08-12
- 只收录首页其他页面都不收录该怎么办 2015-11-07
- 如何解决网站收录少的问题? 2021-10-05
- 关键词seo优化:影响页面收录的因素有哪些 2016-04-13