MapReduce原理及实例分析
前言
成都创新互联公司长期为上千家客户提供的网站建设服务,团队从业经验10年,关注不同地域、不同群体,并针对不同对象提供差异化的产品和服务;打造开放共赢平台,与合作伙伴共同营造健康的互联网生态环境。为临桂企业提供专业的成都做网站、成都网站制作,临桂网站改版等技术服务。拥有十余年丰富建站经验和众多成功案例,为您定制开发。
由于最近开始涉及MR程序的编写,之前会一点HIVE,对MR接触不多,不论从原理还是实际操作上,都有些障碍,终于在今天柳暗花明,将这一过程记录下,与大家分享~
环境准备
在VM上搭建好LINUX虚拟机,并安装配置好HADOOP2.2.0,我这里是单节点的伪分布式 在eclipse中安装hadoop插件 对我们这种MR的新手而言,最好在本地有一个HADOOP运行环境,这样有许多好处: 如果我们每次写完MR程序,都打成JAR包上传至线上服务器上运行,那么每次MR运行的时间非常长,也许等待了许久,运行结果和我们预期不一致,又得改程序重新来一边,这会有一点痛苦! 在我们本地的HADOOP上运行MR程序非常快,就那么几秒,更加重要的是,我们可以再 本地准备输入文件去测试MR的逻辑,这对调试/开发程序非常方便! |
实例及原理分析
假设,我们有这样的输入文件: cate-a spu-1 1 cate-a spu-1 2 cate-a spu-2 3 cate-a spu-2 4 cate-a spu-3 5 cate-a spu-3 6 cate-a spu-1 7 cate-a spu-4 8 cate-a spu-4 9 cate-a spu-1 8 ... 我们希望得到分cate,分spu的总和,并且取分cate分spu的TOP3
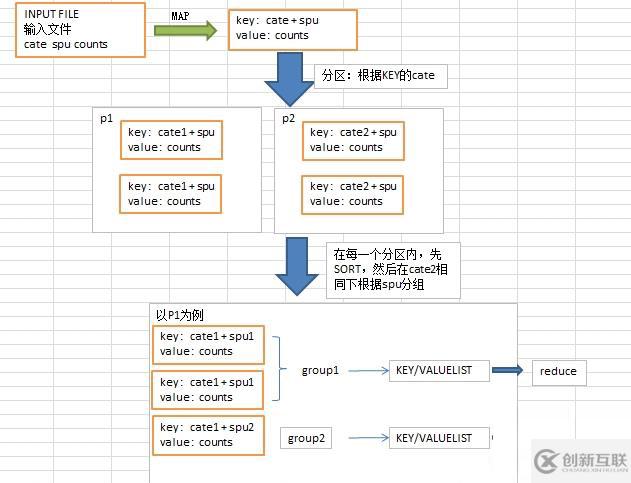
如上图示,大致描述了MAP/REDUCE的运行流程:
步骤:
KEY应该是可序列化,可比较的,只需要注意实现WritableComparable即可。 重点关注compareTo方法。 @Override
public int compareTo(Cate2SpuKey that) {
System.out.println("开始对KEY进行排序...");
if(cate2.equals(that.getCate2())){
return spu.compareTo(that.getSpu());
}
return cate2.compareTo(that.getCate2());
}
分区,是KEY的第一次比较,extends Partitioner 并提供getPartition即可。 这里根据cate分区。
需要注意的是,分组类必须提供构造方法,并且重载 public int compare(WritableComparable w1, WritableComparable w2) 。这里根据cate,spu分组。 通过上述的,就可以取得分cate分spu的SUM(counts)值了。 通过eclipse hadoop插件,可以方便我们上传测试文件到HDFS,可以浏览,删除HDFS文件,更加方便的是,就像运行普通JAVA程序一样的运行/调试MR程序(不在需要打成JAR包),让我们可以追踪MR的每一步,非常方便进行逻辑性测试~
那么怎么取分cate分spu的TOP3呢? 我们只需要把上一个MR的输出文件,作为另一个MR的输入,并且以cate+counts 为KEY ,以spu为VALUE,根据cate分区,分组,排序的话:cate相同情况下,根据counts倒序; 最后在reduce阶段取TOP3即可。 @Override
protected void reduce(Cate2CountsKey key, Iterable<Text> values,
Reducer<Cate2CountsKey, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
System.out.println("reduce...");
System.out.println("VALUES迭代前... key:" + key.toString());
System.out.println("VALUES迭代前... key:" + key.getCounts());
int top = 3;
for(Text t : values){
if(top > 0){
System.out.println("VALUES迭代中... key:" + key.toString());
System.out.println("VALUES迭代中... key:" + key.getCounts());
context.write(new Text(key.getCate2() + "\t" + t.toString()),
new Text(key.getCounts()
+ ""));
top--;
}
}
System.out.println("reduce over...");
}
那么到现在,分组取TOP就完成了。 |
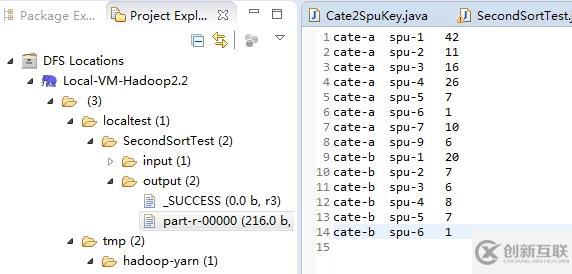
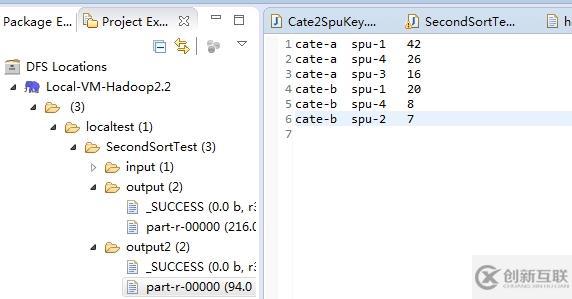
一个疑问:reduce阶段中的KEY到底是什么?
在上面例子中的取TOP3的MR中,我们是以cate+counts为KEY,spu为VALUE。 cate作为分区,分组的依据,排序根据同一个cate下counts倒序。如下图所示:
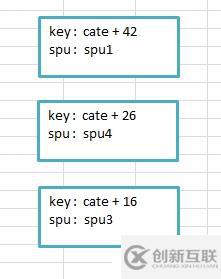
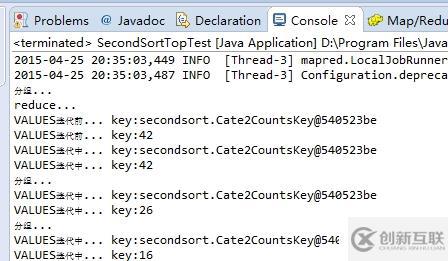
那么reduce方法中的KEY是什么? spu1,spu4,spu3...是VALUES中的,那么这个迭代器的对应KEY是什么呢? 是cate+42吗?还是其他? 在VALUES迭代过程中,这个KEY会变化吗? 我们可以看下ECLIPSE中的控制台打印输出的内容:
从打印上来看,可以分析出如下结论: 分组后,交给reduce方法处理的KEY是同一组的所有KEY的第一个KEY,并且在VALUES迭代过程中,KEY并不会重新NEW,而是利用SETTER反射的方式重新设置属性值,这样在VALUES迭代过程中取得的KEY都是与之对应的KEY了。 |
分享标题:MapReduce原理及实例分析
文章URL:https://www.cdcxhl.com/article10/ghesgo.html
成都网站建设公司_创新互联,为您提供自适应网站、全网营销推广、ChatGPT、品牌网站建设、网站制作、App设计
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 品牌网站设计如何在同行业中脱颖而出? 2016-01-18
- 品牌网站设计应该考虑的问题有哪些? 2023-03-23
- 品牌网站设计要遵守哪些原则 2023-03-11
- 想要做好品牌网站设计的4个要点 2022-01-09
- 吴江高端网站建设制作品牌网站设计如何布局 2020-11-23
- 品牌网站设计的页脚样式是什么 2021-06-20
- 深圳品牌网站设计公司 2014-05-13
- 我要做的是品牌网站设计,实际上是品牌网页优化设计,可懂? 2022-05-23
- 金融网站建设竞争力,品牌网站设计新趋势 2014-06-08
- 好的品牌网站设计两大要点必知 2022-06-10
- 高端品牌网站设计注重的五大要素 2022-08-23
- 品牌网站设计如何做好用户体验 2021-10-03