Redis主从复制高可用集群详解-创新互联
1. 单机故障

如果发生机器故障,例如磁盘损坏,主板损坏等,未能在短时间内修复好,客户端将无法连接redis。
当然如果仅仅是redis节点挂掉了,可以进行问题排查然后重启,姑且不考虑这段时间对外服务的可用性,那还是可以接受的。而发生机器故障,基本是无济于事。除非把redis迁移到另一台机器上,并且还要考虑数据同步的问题。
2. 容量瓶颈
假如一台机器是16G内存,redis使用了12G内存,而其他应用还需要使用内存,假设我们总共需要60G内存要如何去做呢,是否有必要购买64G内存的机器呢?
3. QPS瓶颈
redis官方数据显示可以达到10w的QPS,如果业务需要100w的QPS怎么去做呢?
关于容量瓶颈和QPS瓶颈是redis分布式需要解决的问题,而机器故障就是高可用的问题了。
2、单机故障解决方法在分布式系统中为了解决单点问题,通常会把数据复制多个副本部署到其他机器(主从模式),满足故障恢复和负载均衡的需求。
- 主(Master)和从(Slave)分别部署在不同的服务器上,当主节点服务器写入数据时,同时也会将数据同步到从节点服务器。
- 通常情况下,主节点负责写入数据,从节点负责读出数据
redis也是如此,它为我们提供了复制功能,实现了相同数据的多个redis副本(复制功能是高可用redis的基础,哨兵和集群都是在复制的基础上实现高可用的)。
但是这样会有如下问题,多个副本之间的数据如何保持一致呢?数据读写操作可以发送给所有实例呢?
实际上,Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。
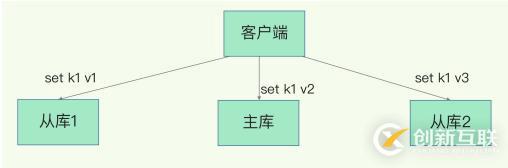
即:

说明:
- redis主机会一直将自己的数据复制给redis从机,从而实现主从同步;
- 在这个过程中,只有master主机可以执行写命令,其他slave从机只能执行读命令;
- 这种读写分离模式可以大大减轻redis主机的数据读取压力,从而提高了redis的效率,并同时提供了多个数据备份;
- 主从模式是搭建Redis Cluster 集群最简单的一种方式;
在了解 Redis 的主从复制之前,让我们先来理解一下现代分布式系统的理论基石——CAP 原理。
CAP 原理是分布式存储的理论基石:
- C:Consistent,一致性
- A:Availability,可用性
- P:Partition tolerance,分区容忍性
分布式系统的节点往往都是分布在不同的机器上进行网络隔离开的,这意味着必然会有网络断开的风险,这个网络断开的场景的专业词汇叫做”网络分区“。
在网络分区发生时,两个分布式节点无法进行通信,我们对一个节点进行的修改操作将无法同步到另外一个节点,所以数据的”一致性“将无法满足,因为两个分布式节点的数据不再保持一致。除非我们牺牲”可用性“,也就是暂停分布式节点服务,在网络分区发生时,不再提供修改数据的功能,直到网络状况完全恢复正常再继续对外提供服务。
一句话概括 CAP 原理就是——网络分区发生时,一致性和可用性两难全。
2、Redis主从同步最终一致性Redis 的主从数据是 异步 复制的,所以分布式的 Redis 系统并不满足一致性要求。当客户端在 Redis 的主节点修改了数据后,立即返回,即使在主从网络断开的情况下,主节点依旧可以正常对外提供服务,所以 Redis 满足可用性。
而 Redis 其实是保证 ”最终一致性“,从节点会努力追赶主节点,最终从节点的状态会和主节点的状态保持一致。如果网络断开了,主从节点的数据将会出现大量不一致,一旦网络恢复,从节点会采用多种策略努力追赶上落后的数据,继续尽力保持和主节点一致。
三、主从复制类型 1、主备与主从1. 主备
请求都只能打到Master主节点上,备机只是等主机挂了后来自动升级为客户端继续提供服务。也就是说他不会为主节点分摊请求压力。
2. 主从
读请求会均摊到主节点和从节点上,而不是等主机挂了才提供服务。写请求在master上进行,然后同步到slaver。读请求会分摊,比如10w个请求,一主双从的话,可能M上3w个,两个S上处理6w个,他会为主节点分摊压力。所以可以解决单点故障问题。
2、主从复制三种类型1. 同步阻塞
这种方式讲究强一致性,必须等所有Slave都写入成功后我才会给客户端响应,否则一直阻塞。也是CAP中的C。
原理图:
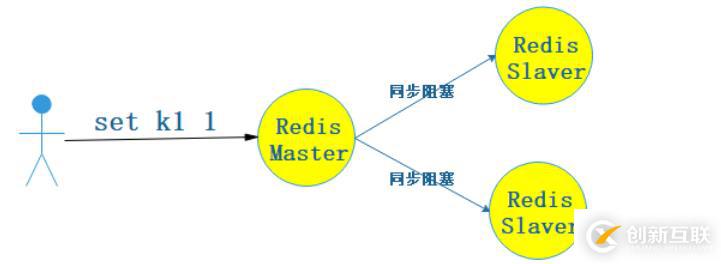
- 优点:数据强一致性(但是会破坏可用性,也就是CAP的A)。
- 缺点:效率低,同步阻塞。
2. 异步非阻塞
Redis采取的这种方式。没有采取下面同步阻塞mq的方式可能也是因为效率吧,因为Redis就是要高效。客户端发完请求到Redis Master后,立马给客户端返回,我不管你Slaver是否同步完成。保留CAP的A,舍弃C。
原理图:
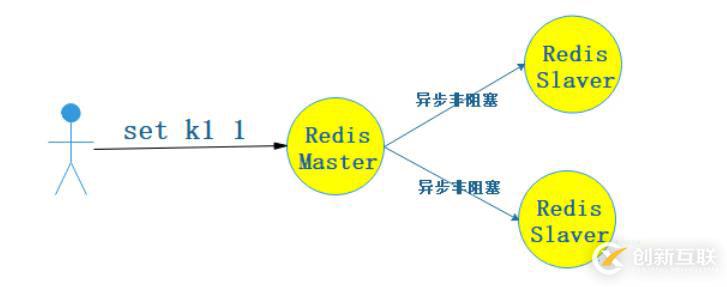
- 优点:效率高,异步非阻塞。
- 缺点:会丢失数据,满足了CAP的A,舍弃了CAP的C。
3. 同步阻塞MQ
大数据hive采取的就是这种方式,他会保证最终一致性。相对于第二种方式好处在于能保证数据的最终一致性,坏处在于没第二种方式高效,但第二种存在丢数据的风险。
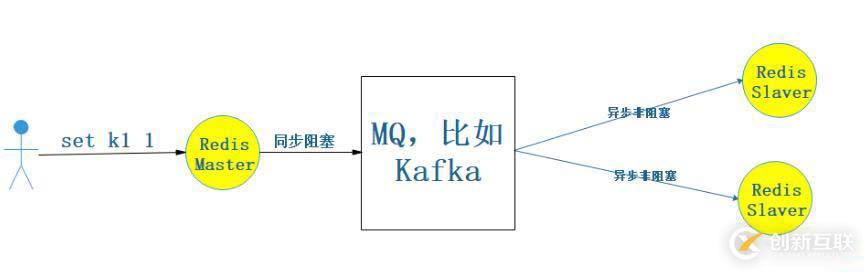
- 优点:效率相对较高、能保证数据最终一致性。
- 缺点:没发现啥缺点。非要说缺点那就是有可能取到不一致的数据,因为不是强一致性。为什么Redis不采取这个?因为Redis要高效率,不想融入太多组件(MQ)进来。
主从复制其实就是实现高可用(虽然是人工操作),避免单点故障问题。挂掉一个节点,我其他节点可以接着提供服务,但是明显缺点发现是Slave挂掉还好,Master挂掉可就难受了,Slave太多的话那就够运维折腾的了,这时候就有了哨兵。 同时,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况,主从复制也能够分担读压力。
主从复制原理图:
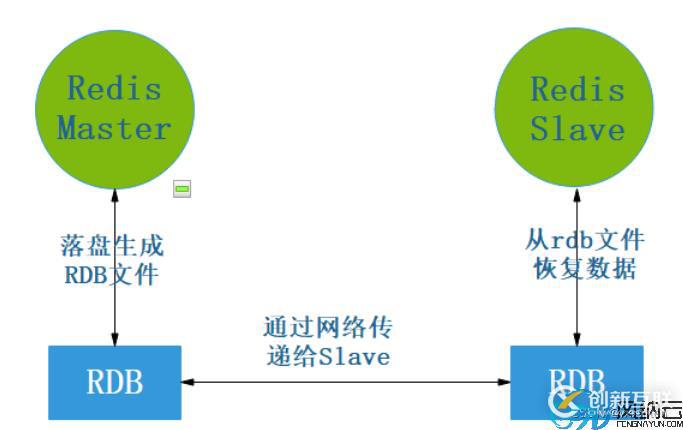
其实就跟MySQL一个道理,mysql是靠binlog,而Redis靠的是rdb文件和aof文件。
2、主从复制实现原理总的来说主从复制功能的详细步骤可以分为7个步骤:
设置主节点的地址和端口-》建立套接字链接-》发送PING命令-》权限验证-》同步-》命令传播
接下来分别叙述每个步骤,整个流程图如下:
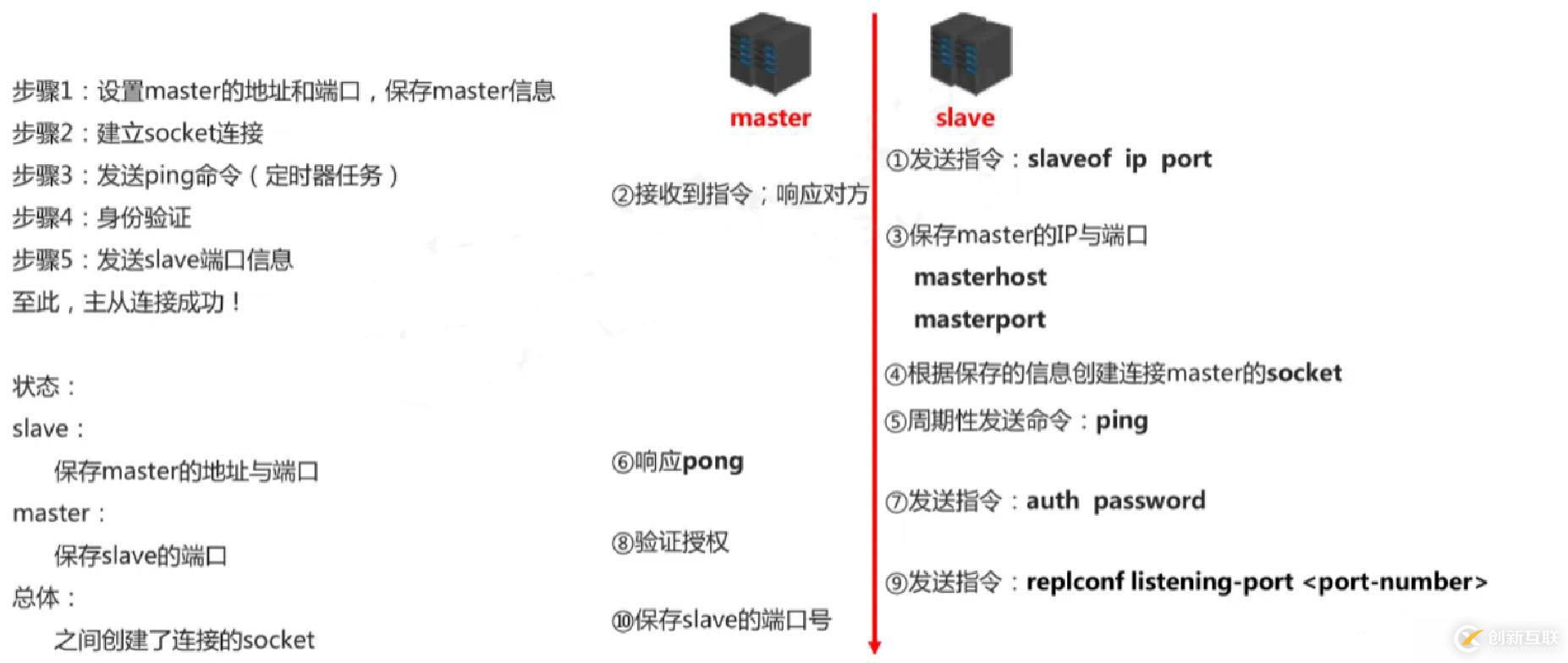
假设在本地机开启两个Redis节点,分别监听:
- 127.0.0.1 6379(主)
- 127.0.0.1 6380(从)
1. 设置主服务器的地址和端口
第一步首先是在从服务器设置需要同步的主服务器信息,包括机器IP,端口。
主从复制的开启,完全是从节点发起;不需要我们在主节点做任何事情。
从节点开启主从复制,有3种方式:
(1)配置文件
在从服务器的配置文件中加入:
slaveof masterip masterport(2)启动命令
redis-server启动命令后加入:
slaveof masterip masterport(3)客户端命令
Redis服务器启动后,直接通过客户端执行命令:
slaveof masterip masterport则该Redis实例称为从节点。
上述3种方法是等效的,下面以客户端命令的方式为例,看一下当执行了slaveof后,Redis主节点和从节点的变化。从服务器会将主服务器的ip地址和端口号保存到服务器状态的属性里面,可以使用Redis命令 info replication 分别查看从服务器和主服务器的主从信息。
2. 建立套接字连接
在slaveof命令执行之后,从服务器会根据设置的ip和端口,向主服务器建立socket连接。
在6380从服务器里面执行完 slave of 127.0.0.1 6379 后意味着,从服务器向主服务器发起 socket 连接。
在执行info Replication 命令分别查看从服务器的主从信息:
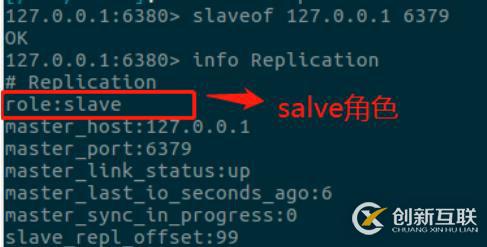
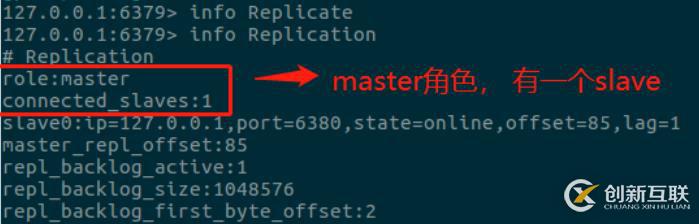
而6379服务器已经成为主服务器角色:
3. 发送PING命令
从节点成为了主节点的客户端之后,发送 ping 命令进行首次请求,目的是:检查socket连接是否可用,以及主节点当前是否能够处理请求。
从节点发送 ping 命令后,可能出现3种情况:
- 返回 PONG:说明socket连接正常,且主节点当前可以处理请求,复制过程继续。
- 超时:一定时间后从节点仍未收到主节点的回复,说明socket连接不可用,则从节点断开socket连接,并重连。
- 返回pong以外的结果:如果主节点返回其他结果,如正在处理超市运行的脚本,说明主节点当前无法处理命令,则从节点端口socket连接,并重连。
4. 身份验证
如果从节点中设置了masterauth选项,则从节点需要向主节点进行身份验证;没有设置该选项,则不需要验证。从节点进行身份验证是通过向主节点发送auth命令进行的,auth命令的参数即为配置文件中的masterauth的值。
如果主节点设置密码的状态,与从节点masterauth的状态一致(一致是指都存在,且密码相同,或者都不存在),则身份验证通过,复制过程继续;如果不一致,则从节点断开socket连接,并重连。
5. 同步
同步就是将从节点的数据库状态更新成主节点当前的数据库状态。具体执行的方式是:从节点向主节点发送psync命令(Redis2.8以前是sync命令),开始同步。
数据同步阶段是主从复制最核心的阶段,根据主从节点当前状态的不同,可以分为 全量复制 和 部分复制。
6. 命令传播
经过上面同步操作,此时主从的数据库状态其实已经一致了,但这种一致的状态并不是一成不变的。
在完成同步之后,也许主服务器马上就接受到了新的写命令,执行完该命令后,主从的数据库状态又不一致。
数据同步阶段完成后,主从节点进入命令传播阶段;在这个阶段主节点将自己执行的写命令发送给从节点,从节点接受命令并执行,从而保证主从节点数据的一致性。
另外命令传播我们需要关注两个点:延迟与不一致 和 心跳机制。
- 延迟与不一致
需要注意的是,命令传播是异步的过程,即主节点发送写命令后并不会等待从节点的回复;因此实际上主从节点之间很难保持实时的一致性,延迟在所难免。数据不一致的程度,与主从节点之间的网路状况、主节点写命令执行频率、以及主节点中repl-disable-tcp-nodelay 配置等有关。
repl-disable-tcp-nodelay 配置如下:
- 假如设置成yes,则redis会合并小的TCP包从而节省带宽,但会增加同步延迟(40ms),造成master与slave数据不一致;
- 假如设置成no,则redis master会立即发送同步数据,没有延迟;
概括来说就是:前者关注性能,后者关注一致性。
一般来说,只有当应用对Redis数据不一致的容忍度较高,且主从节点之间网络状态不好时,才会设置为yes;多数情况使用默认值no
命令传播阶段,从服务器会利用心跳检测机制定时的向主服务发送消息。
3、Redis主从复制结构Redis的主从结构可以采用一主一从、一主多从或者树状主从结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。
一主一从:
- 一主一从是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持
- 当应用写命令并发量较高而且需要持久化时,可以只在从节点开启AOF,这样即保证了数据安全性同时也避免了持久化对主节点的性能干扰
- 但需要注意的是, 当主节点关闭持久化功能时,如果主节点脱机要避免自动重启操作。 因为主节点之前没有开启持久化功能自动重启后数据集为空, 这时从节点如果继续复制主节点会导致从节点数据也被清空的情况, 丧失了持久化的意义。 安全的做法是在从节点上执行slaveof no one断开与主节点的复制关系, 再重启主节点从而避免这一问题。

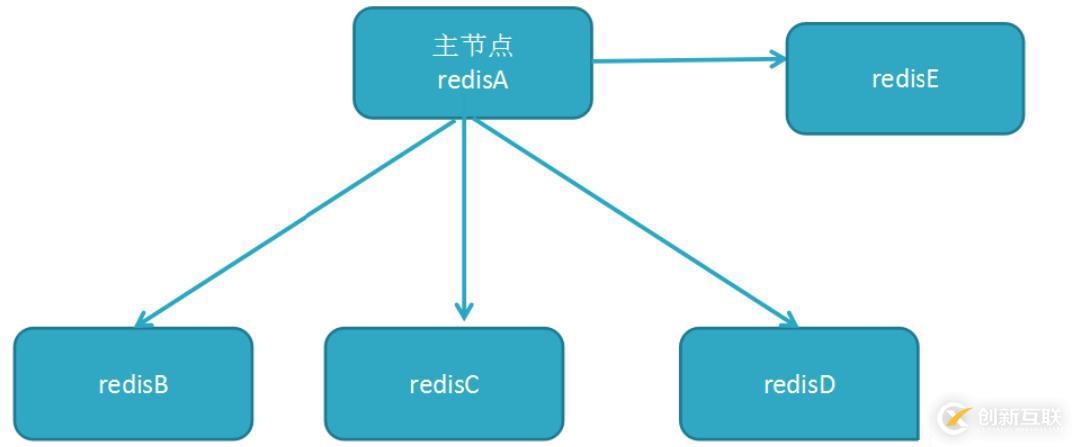
一主多从:
- 一主多从结构(又称为星形拓扑结构) 使得应用端可以利用多个从节点实现读写分离(见图) 。 对于读占比较大的场景, 可以把读命令发送到从节点来分担主节点压力。
- 同时在日常开发中如果需要执行一些比较耗时的读命令, 如: keys、 sort等, 可以在其中一台从节点上执行, 防止慢查询对主节点造成阻塞从而影响线上服务的稳定性。
- 对于写并发量较高的场景, 多个从节点会导致主节点写命令的多次发送从而过度消耗网络带宽, 同时也加重了主节点的负载影响服务稳定性。
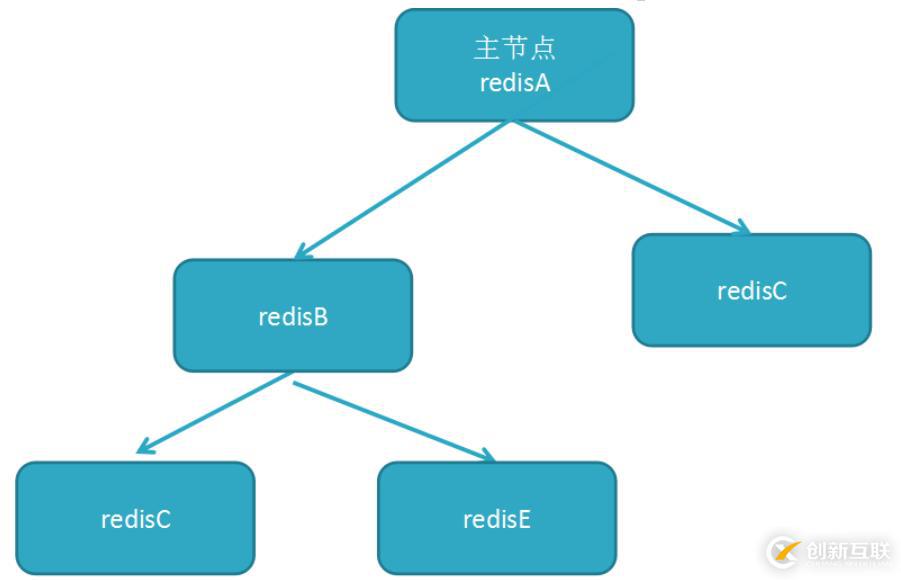
树状主从结构:
- 树状主从结构(又称为树状拓扑结构) 使得从节点不但可以复制主节点数据, 同时可以作为其他从节点的主节点继续向下层复制
- 通过引入复制中间层, 可以有效降低主节点负载和需要传送给从节点的数据量。
- 如图所示, 数据写入节点A后会同步到B和C节点, B节点再把数据同步到D和E节点, 数据实现了一层一层的向下复制。
- 当主节点需要挂载多个从节点时为了避免对主节点的性能干扰, 可以采用树状主从结构降低主节点压力。
在Redis2.8以前,从接待你向主节点发送sync命令请求同步数据,此时的同步方式是全量复制;在Redis2.8及以后,从节点可以发送psync命令请求同步数据,此时根据主从节点当前状态的不同,同步方式可能是全量复制或部分复制。
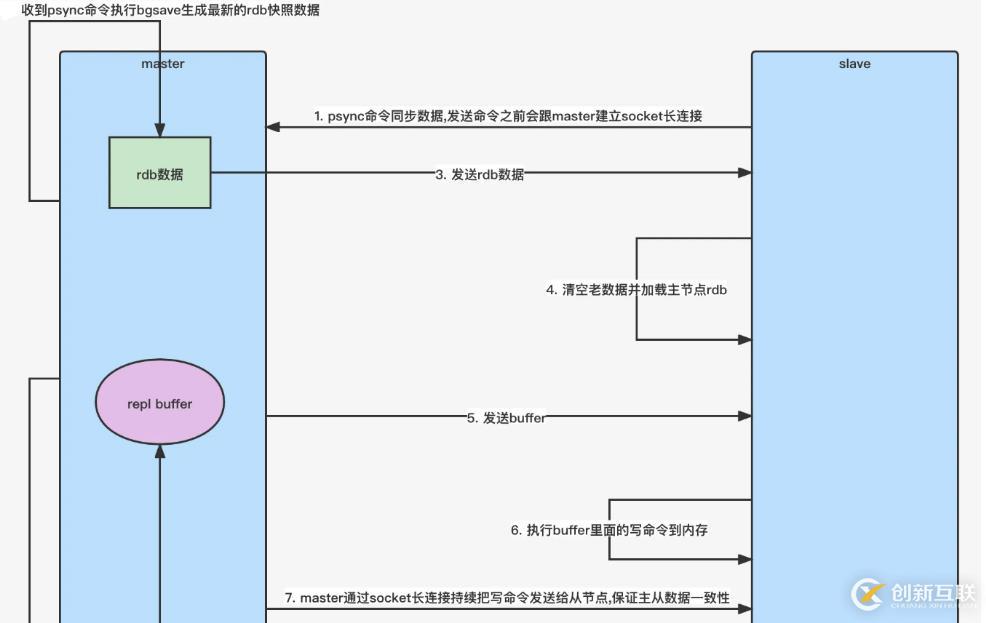
全量复制:用于初次复制或其他无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作。
部分复制:用于网络中断等情况后的复制,只将中断期间主节点执行的写命令发送给从节点,与全量复制相比更加高效,需要注意的是,如果网络中断时间过长,导致主节点没有能够完整地保存中断期间执行地写命令,则无法进行部分复制,仍使用全量复制。
1. 全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。

具体步骤如下:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
2. 增量同步
由于全量复制在主节点数据量较大时效率太低,因此Redis2.8开始提供部分复制,用于处理网络中断时的数据同步。
部分复制的实现,依赖于三个重量的概念:复制偏移量、复制积压缓冲区、服务器运行id(runid)
1)复制偏移量
执行复制的双方,主从节点,分别会维护一个复制偏移量offset:
- 主节点每次向从节点同步了N字节数据后,将自己的复制偏移量offset+N
- 从节点每次从主节点同步了N字节数据后,将修改自己的复制偏移量offset+N
offset用于判断主从节点的数据库状态是否一致:如果二者offset相同,则一致;如果offset不同,则不一致,此时可以根据两个offset找出从节点缺少的那部分数据。例如,如果主节点offset是1000,而从节点的offset是500,那么部分复制旧需要将offset为501-1000的数据传递给从节点。而offset为501-1000的数据存储的位置,就是下面要介绍的复制积压缓冲区。
2)复制积压缓冲区(replication-backlog-buffer)
主节点内部维护了一个固定长度的、先进先出(FIFO)队列作为复制积压缓冲区,默认大小为1MB,在主节点进行命令传播时,不仅会将写命令同步到从节点,还会将写命令写入复制积压缓冲区。
由于复制积压缓冲区定长且是先进先出,所以他保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。因此,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。
为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size);例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(某些特定协议格式)所占据的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:
- 如果offset偏移量之后的数据,仍然都在复制积压缓冲区例,则执行部分复制;
- 如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
3)服务器运行ID(runid)
每个Redis节点,都有其运行ID,运行ID由节点在启动时自动生成,主节点会将自己的运行ID发送给从节点,从节点会将主节点的运行ID存起来。从节点Redis断开重连的时候,就是根据运行ID来判断同步的进度:
如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况);
如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
4、psync命令的执行在了解了复制偏移量、复制积压缓冲区、节点运行id之后,这里psync命令的参数和返回值,从而说明psync命令执行过程中,主从节点是如何确定使用全量复制还是部分复制的。
psync命令流程图如下:

psync命令的大体流程如下:
如果从节点之前没有复制过任何主节点,或者之前执行过slaveof no one 命令,从节点就会向主节点发送psync 命令,请求主节点进行数据的全量同步。
如果前面从节点已经同步过部分数据,此时从节点就会发送psync runid offset 命令给主节点,其中runid是上一次主节点的运行ID,offset是当前从节点的复制偏移量
主节点收到psync命令后,会出现以下三种可能:
主节点返回 fullresync runid offset 回复,表示主节点要求与从节点进行数据的完整全量复制,其中runid表示主节点的运行ID,offset表示当前主节点的复制偏移量。
如果主服务器返回+continue,表示从节点与从节点会进行部分数据的同步操作,将从节点缺失的数据复制过来即可。
如果主服务器返回-err,表示主服务器的Redis版本低于2.8,无法是别psync命令,此时从服务器会向主服务器发送sync,进行完整的数据全量复制。
Redis通过psnyc命令进行全量复制的过程如下:
- 从节点判断无法进行部分复制,向主节点发送全量复制的请求;或从节点发送部分复制的请求,但主节点判断无法进行部分复制;
- 主节点收到全量复制的命令后,执行bgsave,在后台生成RDB文件,并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令;
- 主节点的bgsave执行完成后,将RDB文件发送给从节点;从节点首先清除自己的旧数据,然后载入接收的RDB文件,将数据库状态更新至主节点执行bgsave时的数据库状态;
- 主节点将前述复制缓冲区中的所有写命令发送给从节点,从节点执行这些写命令,将数据库状态更新至主节点的最新状态;
- 如果从节点开启了AOF,则会触发bgrewriteaof的执行,从而保证AOF文件更新至主节点的最新状态;
通过全量复制的过程可以看出,全量复制是非常重型的操作:
- 主节点通过bgsave命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页表复制)、磁盘IO的;
- 主节点通过网络将RDB文件发送给从节点,对主从节点的带宽都会带来很大的消耗;
- 从节点清空老数据、载入新RDB文件的过程是阻塞的,无法响应客户端的命令;如果从节点bgrewriteaof,也会带来额外的消耗;
心跳检测机制的作用有三个:
- 检查主从服务器的网络连接状态;
- 辅助实现min-slaves选项;
- 检测命令丢失;
检查主从服务器的网络连接状态,主节点信息中可以看到所属的从节点的连接信息:
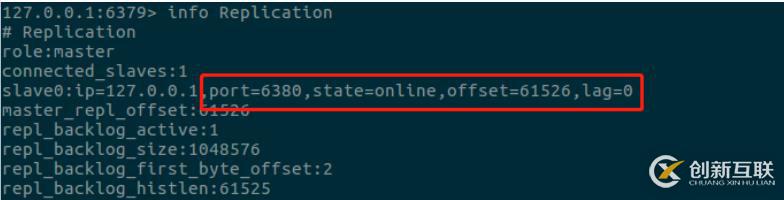
state 表示从节点状态、offset表示复制偏移量、lag表示延迟值(几秒之前有过心跳检测机制)
辅助实现min-slaves选项,Redis.conf 配置文件中有下方两个参数:
# 未达到下面两个条件时,写操作就不会被执行
# 最少包含的从服务器
# min-slaves-to-write 3
# 延迟值
# min-slaves-max-lag 10如果将两个参数注释取消,那么如果从服务器的数量少于3个,或者三个从服务器的延迟(lag)大于等于10秒时,主服务器都会拒绝执行写命令。
检测命令丢失时,在从服务器的连接信息中可以看到复制偏移量,如果此时主服务器的复制偏移量与从服务器的复制偏移量不一致时,主服务器会补发缺失的数据。
5、无磁盘复制通常来讲,一个完全重新同步需要在磁盘上创建一个RDB文件,然后加载这个文件以便为从服务器发送数据。如果使用比较低速的磁盘,这种操作会给主服务器带来较大的压力。Redis从2.8.18版本开始尝试支持无磁盘的复制。使用这种设置时,子进程直接将RDB通过网络发送给从服务器,不使用磁盘作为中间存储,避免了IO性能差问题。
可以使用repl-diskless-sync 配置参数来启动无磁盘复制。使用repl-diskless-sync-delay参数来配置传输开始的延迟时间,以便等待更多的从服务器连接上来。
开启无磁盘复制:
repl-diskless-sync yes如果在主从复制架构中出现宕机的情况,需要分情况看:
1. 从Redis宕机
这个相对而言比较简单,在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据,这是因为在Redis2.8版本后就新增了增量复制功能,主从断线后恢复是通过增量复制实现的。所以这种情况无需担心。
2. 主Redis宕机
这个情况相对而言就会复杂一些,需要以下2步才能完成:
第一步,在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务;
第二步,将主库修复重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来;
这两个步骤要通过手动完成恢复,过程其实是比较麻烦的并且容易出错,有没有好办法解决呢?有的,Redis提供的哨兵(sentinel)功能就可以实现主Redis宕机的自动切换。
7、Redis主从复制总结1. Redis主从复制策略
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。redis的策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
2. 主从复制的特点
主从复制的特点:
- 采用异步复制;
- 一个主redis可以含有多个从redis;
- 每个从redis可以接收来自其他从redis服务器的连接;
- 主从复制对于主redis服务器来说是非阻塞的,这意味着当从服务器在进行主从复制同步过程中,主redis仍然可以处理外界的访问请求;
- 主从复制对于从redis服务器来说也是非阻塞的,这意味着,即使从redis在进行主从复制过程中也可以接受外界的查询请求,只不过这时候从redis返回的是以前老的数据,如果你不想这样,那么在启动redis时,可以在配置文件中进行设置,让redis在复制同步过程中对来自外界的查询请求都返回错误给客户端;(虽然说主从复制过程中,对于从redis是非阻塞的,但是当从redis从主redis同步过来最新的数据后,还需要将新数据加载到内存中,在加载到内存的过程中是阻塞的,在这段时间内的请求将会被阻);
- 主从复制提高了redis服务的扩展性,避免单个redis服务器的读写访问压力过大的问题,同时也可以给为数据备份及冗余提供一种解决方案;
- 为了避免主redis服务器写磁盘压力带来的开销,可以配置让主redis不在将数据持久化到磁盘,而是通过连接让一个配置的从redis服务器及时的将相关数据持久化到磁盘,不过这样会存在一个问题,就是主redis服务器一旦重启,因为主redis服务器数据为空,这时候通过主从同步可能导致从redis服务器上的数据也被清空;所以要避免主redis自动重启。
主从模式并不完美,它也存在许多不足之处,下面做了简单地总结:
- redis主从模式不具备自动容错和恢复功能,如果主节点宕机,redis集群将无法工作,此时需要人为干预,将从节点提升为主节点
- 如果主机宕机前有一部分数据未能及时同步到从机,及时切换主机后也会造成数据不一致的问题,从而降低了系统的可用性
- 因为只有一个主节点,所以其写入能力和存储能力都受到一定的限制
- 在进行数据全量同步时,如果同步的数据量较大可能会造成卡顿的现象
虽然主从模式存在上述不足,但他仍然是实现分布式集群的基础。Sentinel哨兵模式同样是依赖于主从模式实现。
五、Redis主从复制实战 1、主从复制配置文件redis.config配置文件相关配置:
- slaveof
:复制选项,slave复制对应的master的ip和端口。 - masterauth
:如果master设置了requirepass,那么slave要连上master,需要有master的密码才行。masterauth就是用来配置master的密码,这样可以在连上master后进行认证。 - slave-serve-stale-data yes:当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求;2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。
- slave-read-only yes:作为从服务器,默认情况下是只读的(yes),可以修改成NO,用于写(不建议)。
- repl-diskless-sync no:是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法增量同步,就会执行全量同步,master会生成rdb文件。有2种方式:1)disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave;2)socket是master创建一个新的进程,直接将RDB通过网络发送给slave,不使用磁盘作为中间存储。disk方式的时候,rdb是作为一个文件保存在磁盘上,因此多个slave都能共享这个rdb文件。socket方式的复制(无盘复制)是基于顺序的串行复制(master会等待一个repl-diskless-sync-delay的秒数,如果没slave来注册话,就直接传,后来的slave得排队等待。已注册的就可以一起传)。在磁盘速度缓慢,网速快的情况下推荐用socket方式。
- repl-diskless-sync-delay 5:无磁盘复制的延迟时间,不要设置为0。因为一旦复制开始,master节点不会再接收新slave的复制请求,直到这个rdb传输完毕。所以最好等待一段时间,等更多的slave注册上到master后一起传输,提供同步性能。
- repl-ping-slave-period 10:slave根据指定的时间间隔向服务器发送ping请求。时间间隔可以通过 repl_ping_slave_period 来设置,默认10秒。
- repl-timeout 60:复制连接超时时间。master和slave都有超时时间的设置。master检测到slave上次发送的时间超过repl-timeout,即认为slave离线,清除该slave信息。slave检测到上次和master交互的时间超过repl-timeout,则认为master离线。需要注意的是repl-timeout需要设置一个比repl-ping-slave-period更大的值,不然会经常检测到超时。
- repl-backlog-size 5mb:复制缓冲区大小,这是一个环形复制缓冲区,用来保存最新复制的命令。这样在slave离线的时候,不需要完全复制master的数据,如果可以执行部分同步,只需要把缓冲区的部分数据复制给slave,就能恢复正常复制状态。缓冲区的大小越大,slave离线的时间可以更长,复制缓冲区只有在有slave连接的时候才分配内存。没有slave的一段时间,内存会被释放出来,默认1m。
- repl-backlog-ttl 3600:master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。
配置主从:
# 相当于我们上面客户端执行的REPLICAOF命令,配置到配置文件每次重启就不用手动再执行命令了。
replicaof# master的密码
masterauth 主从传输数据这期间,从节点是否允许对外提供服务:
# 默认是ye,允许
slave-serve-stale-data yes看下面的log(这是我们建立主从关系的时候产生的log)。
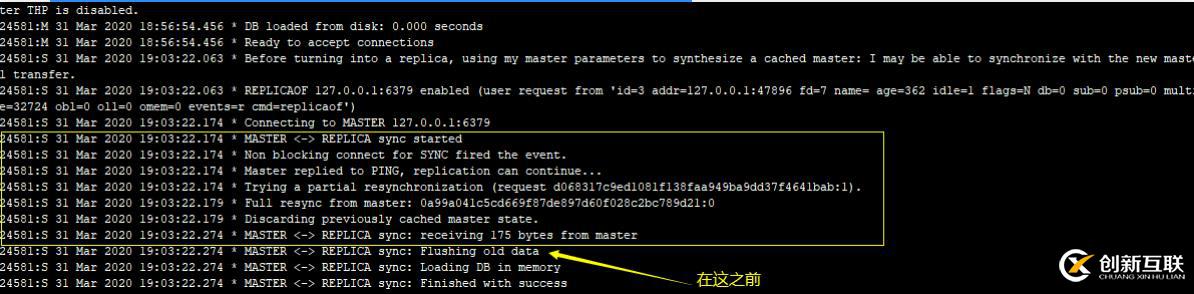
意思是说在和Master建立连接,获取完Master数据之间,也就是从库进行flush操作之前,是否允许对外继续提供请求(就是Slave完成配置之前的那些flush之前的老数据是否还允许被访问)。
是否开启Slave从节点也支持写命令:
# 默认只读,yes代表只读
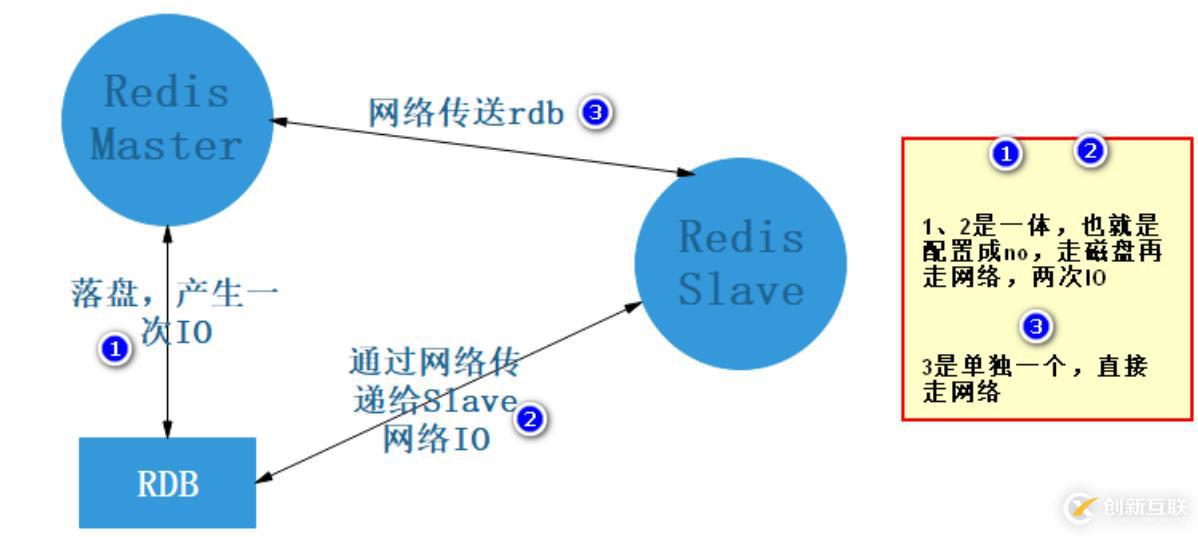
slave-read-only yes先落磁盘再传输还是直接网络传输:
# 默认是先落盘,再进行网络传输
repl-diskless-sync no因为默认是Master先生成rdb文件到磁盘,这时候产生一次磁盘IO,然后将磁盘上rdb文件以网络的方式传递给Slave,这时候又产生一次IO,如果rdb几个GB的话那还不如直接走网络传输,就不走磁盘io了。 改为yes的话直接Master通过网络的方式发送rdb给Slave。默认是no,从日志也可以看出先落盘了

原理图:
全量还是增量:
repl-backlog-size 1mb可以发现比主从复制原理图中多了个队列和偏移量。
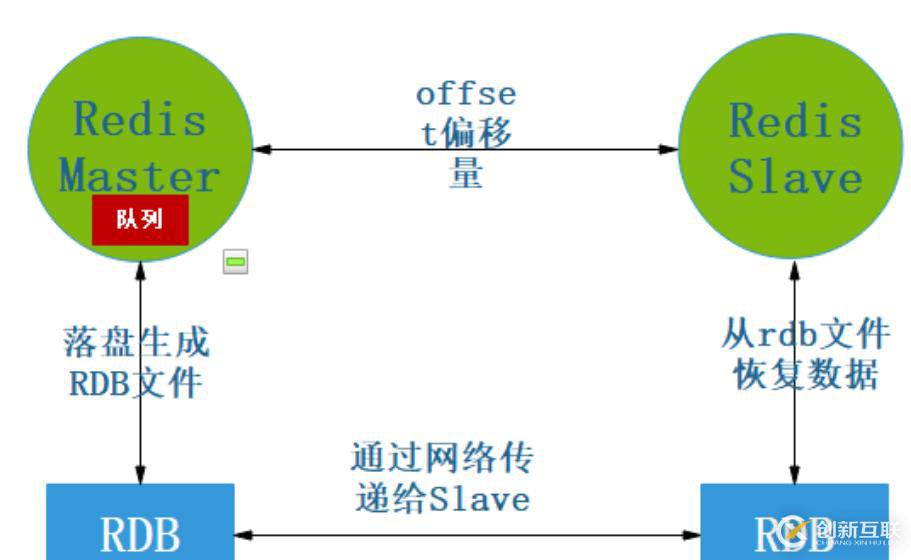
这个队列代表repl-backlog-size参数设置的值大小,是决定全量复制还是增量复制的关键参数。
RDB每次同步到slave的时候,slave都会记录一个offset偏移量,然后每次同步数据的时候都会看队列里的数据偏移量是否符合slave上次同步的数据大小,若符合则增量,否则全量。
举例:
如果设置的1MB,你挂了3s钟,假设1s钟就写了1MB,那么3s钟的队列肯定放不下,这时候就触发全量,所以这个需要看业务调整大小。
再比如master是100MB数据,slave也是1MB数据,然后slave挂了。恢复的时候发现master已经有110MB了,但是队列大小只有1MB,把队列里的数据拿来显然不行,所以会触发全量,这只是举例,其实不会那么傻的判断总大小,而是通过偏移量来的。
2、仅开启RDB仅仅开启RDB持久化,关闭AOF。
首先启动三个redis,端口分别是6379、6380、6381。我们这里设定6379为Master,其余两个为Slaver。
1. 如何设置Slaver

可以看到Redis5.x后开始用REPLICAOF命令代替5.x版本之前的SLAVEOF命令。
2. 设置Slaver
# 设置6380是6379的从节点
127.0.0.1:6380>REPLICAOF localhost 6379
OK设置完成后去看6379和6380的log
6379的log:

6380的log:

3. 在Master执行写命令
127.0.0.1:6379>set k1 123
OK
127.0.0.1:6379>get k1
"123"4. 在Slave(6380)上查看是否同步过来了
127.0.0.1:6380>keys *
1) "k1"
127.0.0.1:6380>get k1
"123"5. Slave是禁止执行写命令的
127.0.0.1:6380>set k2 123
(error) READONLY You can't write against a read only replica.6. 设置6382也作为6379的Slave
设置从节点之前先在6382内set一个值,为了确定设置完后会进行flush操作。
127.0.0.1:6381>set k2 222
OK
127.0.0.1:6381>get k2
"222"然后设置Slave:
127.0.0.1:6381>REPLICAOF 127.0.0.1 6379
OK
127.0.0.1:6381>keys *
1) "k1"将Master的数据同步过来了。
如果设置Slave后进行了flush操作(上面的log也体现出来了),我们之前的k2没了。
若6381宕机了,这时候他再启动的时候是会同步Master的数据的,增量同步的。不需要手动进行同步。
但前提是需要作为Master的Slave,有如下三种方式:
- 客户端执行REPLICAOF;
- 启动Redis的时候添加 --REPLICAOF 127.0.0.1 6379,比如 service redis_6381 start --REPLICAOF 127.0.0.1 6379;
- 修改配置文件;
8. Master挂了怎么办
从节点会一直报错:

导致的问题:Slave无法提供写请求,只能读了。影响了业务使用。
解决方案:让其中一个Slave升级为Master,然后其他Slave作为这个新升级为Master的从。
# 升级为Master的方法:在客户端执行,比如我们升级6380为Master
127.0.0.1:6380>REPLICAOF no one
OK
# 这时候再看6380就不会再刷错了,但是6381还在刷,
# 因为6381是已经挂掉的6379的Slave,我们需要让6381作为6380的Slave,
# 我们再操作这步骤之前,对6380set一个key,然后看6381的数据会重新复制6380的数据
# 显示业务中几乎不会存在此情况,因为从节点升级就是升级,所有主从的数据都一致,不会随意改
# 这里只是演示效果而已。
127.0.0.1:6380>set kkk 3333
OK
# 6381作为6380的Slave
127.0.0.1:6381>REPLICAOF 127.0.0.1 6380
OK
127.0.0.1:6381>keys *
1) "kkk"
2) "k1"
127.0.0.1:6381>get kkk
"3333"1. 仅开启AOF
和上面一样。只是会按照aof文件进行主从复制数据。
2. 混合模式(RDB+AOF)
流程和仅开启RDB一样,只是主从复制的时候会优先按照aof来同步数据,因为aof文件丢失数据最少,更可靠。redis会判断aof文件是否存在,若开启了aof且文件存在,则以aof复制,若没开启aof则走rdb方式。
4、Redis主从复制实战
1. 使用命令实现
1)方法一
使用命令在服务端搭建主从模式,其语法格式如下:
redis-server --port--slaveof 执行以下命令:
#开启开启一个port为6300的从机,它依赖的主机port=6379
>redis-server --port 6300 --slaveof 127.0.0.1 6379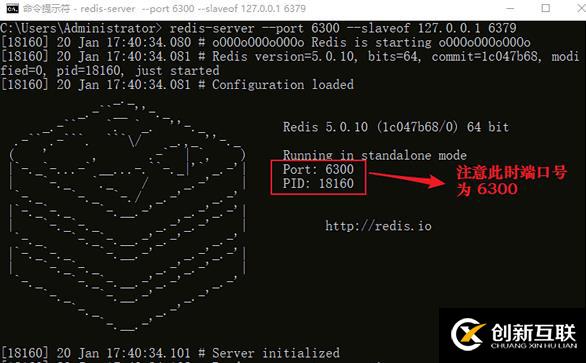
接下来开启客户端,并执行查询命令,如下所示:
>redis-cli -p 6300
127.0.0.1:6300>get name
"jack"
127.0.0.1:6300>get website
"www.biancheng.net"
#不能执行写命令
127.0.0.1:6300>set myname BangDe
(error) READONLY You can't write against a read only slave.
127.0.0.1:6300>keys *
1) "myset:__rand_int__"
2) "ID"
3) "title"
4) "course2"从上述命令可以看出,port =6300 的主机,完全备份了主机的数据,它可以执行查询命令,但不能执行写入命令
从机服务端提示如下:
[18160] 20 Jan 17:40:34.101 # Server initialized #服务初始化
[18160] 20 Jan 17:40:34.108 * Ready to accept connections #准备连接
[18160] 20 Jan 17:40:34.108 * Connecting to MASTER 127.0.0.1:6379 #连接到主服务器
[18160] 20 Jan 17:40:34.109 * MASTER<->REPLICA sync started #启动副本同步
[18160] 20 Jan 17:40:34.110 * Non blocking connect for SYNC fired the event.#自动触发SYNC命令,请求同步数据
[18160] 20 Jan 17:40:34.110 * Master replied to PING, replication can continue...
[18160] 20 Jan 17:40:34.112 * Partial resynchronization not possible (no cached master)
[18160] 20 Jan 17:40:34.431 * Full resync from master: 6eb220706f73107990c2b886dbc2c12a8d0d9d05:0
[18160] 20 Jan 17:40:34.857 * MASTER<->REPLICA sync: receiving 6916 bytes from master #从主机接受了数据,并将其存在于磁盘
[18160] 20 Jan 17:40:34.874 * MASTER<->REPLICA sync: Flushing old data #清空原有数据
[18160] 20 Jan 17:40:34.874 * MASTER<->REPLICA sync: Loading DB in memory #将磁盘中数据载入内存
[18160] 20 Jan 17:40:34.879 * MASTER<->REPLICA sync: Finished with success #同步数据完成可以看出主从模式下,数据的同步是自动完成的,这个数据同步的过程,又称为全量复制。
2)方法二
启动一个服务端,并指定端口号。
#指定端口号为63001,不要关闭
redis-server --port 63001打开一个客户端,连接服务器,如下所示:
# 连接port=63001的服务器
>redis-cli -p 63001
// 现在处于主机模式下,所以运行读写数据
127.0.0.1:63001>keys *
1) "name"
127.0.0.1:63001>get name
"aaaa"
127.0.0.1:63001>set name "bbbb"
OK
127.0.0.1:63001>get name
"bbbb"
127.0.0.1:63001># 将当前服务器设置为从服务器,从属于6379
127.0.0.1:63001>SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:63001>keys *
1) "master_6379" # 现在它的数据和主服务器的数据一样了
#写入命令执行失败
127.0.0.1:63001>SET mywebsite www.biancheng.net
(error) READONLY You can't write against a read only replica.
#再次切换为主机模式,执行下面命令
127.0.0.1:63001>SLAVEOF no one
OK
127.0.0.1:63001>SLAVEOF no one
OK
127.0.0.1:63001>keys *
1) "master_6379" # 数据还是和之前主服务器的一样
127.0.0.1:63001>SET mywebsite www.biancheng.net # 但是现在可以写入命令了
OK
127.0.0.1:63001>keys *
1) "mywebsite"
2) "master_6379"
2. 修改配置文件实现
每个 Redis 服务器都有一个与其对应的配置文件,通过修改该配置文件也可以实现主从模式。
新建 redis_6302.conf 文件,并添加以下配置信息:
slaveof 127.0.0.1 6379 #指定主机的ip与port
port 6302 #指定从机的端口启动 Redis 服务器,执行以下命令:
$ redis-server redis_6302.conf客户端连接服务器,并进行简单测试。
执行以下命令:
$ redis-cli -p 6302
127.0.0.1:6300>HSET user:username biangcheng
#写入失败
(error) READONLY You can't write against a read only slave.通过命令搭建主从模式,简单又快捷,所以不建议使用修改配置文件的方法。
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
本文题目:Redis主从复制高可用集群详解-创新互联
文章网址:https://www.cdcxhl.com/article10/ddgego.html
成都网站建设公司_创新互联,为您提供响应式网站、网站改版、外贸网站建设、搜索引擎优化、定制网站、自适应网站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 电子商务的特点 2022-02-23
- 做一个电子商务网站 2021-04-19
- 电子商务网站设计需注意什么? 2015-02-06
- 电子商务师基础常识辅导:四步网络推广 2022-11-10
- 成功的电子商务网站设计6要素 2014-04-06
- 昭通网站建设-电子商务时代,网站建设的必要性 2021-09-21
- 对于电子商务网站的各种情况分析 2021-06-02
- 电子商务网站最关键的是用户体验 2021-06-29
- 电子商务跑马圈地又一轮摒弃浮躁修炼内功 2022-11-20
- 电子商务网站建设的必要性 2021-04-14
- 电子商务影响财务管理模式在六方面的表现 2015-07-07
- 电子商务网站建设的重要性和好处 2021-09-05