C++编程笔记(GPU并行编程-2)-创新互联
封装
利用标准库容器实现对GPU的内存管理
#include#include#include#includetemplatestruct CUDA_Allocator {using value_type = T; //分配器必须要有的
T *allocate(size_t size) {T *dataPtr = nullptr;
cudaError_t err = cudaMallocManaged(&dataPtr, size * sizeof(T));
if (err != cudaSuccess) { return nullptr;
}
return dataPtr;
}
void deallocate(T *ptr, size_t size = 0) {cudaError_t err = cudaFree(ptr);
}
};
__global__ void kernel(int *arr, int arrLen) {for (int i = blockDim.x * blockIdx.x + threadIdx.x; i< arrLen; i += blockDim.x * gridDim.x) {arr[i] = i;
//printf("i=%d\n", i);
}
}
int main() {int size = 65523;
std::vector>arr(size);
kernel<<<13, 28>>>(arr.data(), size);
cudaError_t err = cudaDeviceSynchronize();
if (err != cudaSuccess) {printf("Error:%s\n", cudaGetErrorName(err));
return 0;
}
for (int i = 0; i< size; ++i) {printf("arr[%d]=%d\n", i, arr[i]);
}
} 其中allocate和deallocate是必须实现的
这里不用默认的std::allocate,使用自己定义的分配器,使得内存分配在GPU上
vector是会自动初始化的,如果不想自动初始化的化,可以在分配器中自己写构造函数
关于分配器的更多介绍
#includeint main(){//使用的是共享内存
thrust::universal_vectorarr(size);
} 或者
#include#include thrust::device_vectordVec(100);
//重载了=符号,会自动拷贝内存,这里是将GPU内存拷贝到CPU,
thrust::host_vectorhVec = dVec; template__global__ void para_for(int n, Func func) {for (int i = blockDim.x * blockIdx.x + threadIdx.x; i< n; i += blockDim.x * gridDim.x) {func(i);
}
}
//定义一个仿函数
struct MyFunctor {__device__ void operator()(int i) {printf("number %d\n", i);
}
};
int main() {int size = 65513;
para_for<<<13,33>>>(size,MyFunctor{});
cudaError_t err = cudaDeviceSynchronize();
if (err != cudaSuccess) {printf("Error:%s\n", cudaGetErrorName(err));
return 0;
}
} 同样的,lambda也是被支持的,但是要先在cmake中开启
target_compile_options(${PROJECT_NAME} PUBLIC $<$:--extended-lambda>) 
lambda写法
para_for<<<13, 33>>>(size, [] __device__(int i) {printf("number:%d\n", i); });lambda捕获外部变量
一定要注意深拷贝和浅拷贝
如果这里直接捕获arr的话,是个深拷贝,这样是会出错的,因为拿到的arr是在CPU上的,而数据是在GPU上的,所以这里要浅拷贝指针,拿到指针的值,就是数据在GPU上的地址,这样就可以使用device函数对数据进行操作了
std::vector>arr(size);
int*arr_ptr=arr.data();
para_for<<<13, 33>>>(size, [=] __device__(int i) {arr_ptr[i] = i; });
cudaError_t err = cudaDeviceSynchronize();
if (err != cudaSuccess) {printf("Error:%s\n", cudaGetErrorName(err));
return 0;
}
for (int i = 0; i< size; ++i) {printf("arr[%d]=%d\n", i, arr[i]);
} 同时还可以这样捕获
para_for<<<13, 33>>>(size, [arr=arr.data()] __device__(int i) {arr[i] = i; });#include#define TICK(x) auto bench_##x = std::chrono::steady_clock::now();
#define TOCK(x) std::cout<< #x ": "<< std::chrono::duration_cast>(std::chrono::steady_clock::now() - bench_##x).count()<< "s"<< std::endl;
int main(){int size = 65513;
std::vector>arr(size);
std::vectorcpu(size);
TICK(cpu_sinf)
for (int i = 0; i< size; ++i) {cpu[i] = sinf(i);
}
TOCK(cpu_sinf)
TICK(gpu_sinf)
para_for<<<16, 64>>>(
size, [arr = arr.data()] __device__(int i) {arr[i] = sinf(i); });
cudaError_t err = cudaDeviceSynchronize();
TOCK(gpu_sinf)
if (err != cudaSuccess) {printf("Error:%s\n", cudaGetErrorName(err));
return 0;
}
} 结果: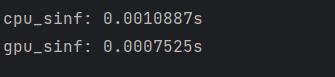
可以看到,求正弦GPU是要快于CPU的,这里差距还不明显,一般来说速度是由数量级上的差距的
学习链接
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
分享标题:C++编程笔记(GPU并行编程-2)-创新互联
地址分享:https://www.cdcxhl.com/article0/copgoo.html
成都网站建设公司_创新互联,为您提供品牌网站设计、网站改版、微信公众号、网站内链、网站设计公司、服务器托管
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 手机网站跟微信结合的一些方法 2016-10-24
- 手机网站与微官网的区别有哪些? 2016-08-23
- 网站制作团队应该有哪些方面的成员 2014-10-12
- 网站维护比自招员工更靠谱的是委托网站建设公司 2022-05-19
- 营销型外贸网站改版须知 2013-05-19
- 响应式网站和自适应网站会有什么样的区别? 2016-08-24
- 后台管理设计合理 高标准企业网站维护更方便 2016-12-15
- 成都世通集团与创新互联网站改版签约 2015-03-22
- 网站维护有哪些 2023-03-23
- 做好企业网站维护需要具备哪些知识 2023-02-05
- 网站维护对网站有这什么样的作用? 2022-09-23
- 企业该如何用好处于红利期的小程序突破业绩增长? 2016-10-17