【计算机体系结构-02】机器模型-创新互联
计算机的基本工作就是进行运算,那么计算就需要有用来处理计算方法的处理单元和提供或保存数值的存储单元。一般将用来处理计算方法的处理单元称为 算术逻辑单元 (ALU--Arithmetic Logic Unit)。在一个计算过程中可能会是这样的一个流程,从存储单元中取出一些数据,放进ALU中进行计算,然后将计算结果保存到存储单元中。
那么完成这个计算流程的机器模型是如何利用存储单元和算术逻辑单元构建起来的?该如何访问存储器?机器模型该允许什么样的指令和操作?操作数怎么获取从哪来?结果又该放在哪?
⭐
首先明确一点,机器模型不是指令集架构,上篇文章《【计算机体系结构-01】指令集体系结构、微体系结构简介》已经说明了,指令集架构是为软件编程提供的一种规范,它是关于计算和操作指令如何封装制定的一套标准,而 机器模型则是一种更加基础的理论,是构建出存储器和 ALU 的物理结构,从而确定数据如何移动,又如何从 ALU 移动到存储器。
不管你信不信,在一个处理器中是可以没有寄存器的(寄存器不是必要的)。OK,来看一个历史上实际搭建过的处理器,它的结构非常简单。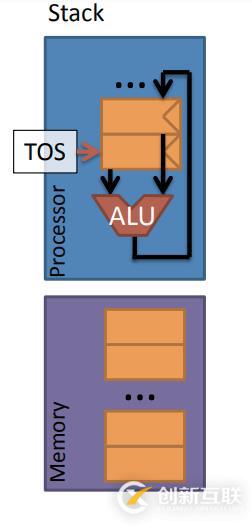
那么可以看图片中的这种机器模型,利用栈结构存储,而栈只是一个存储器,并非寄存器。栈的结构相信大家已经很清楚,数据会遵循先入后出的顺序入栈、出栈。这个 机器模型的工作流程很简单,只需要从栈顶开始取两个元素,通过 ALU 计算,然后将结果保存栈顶。
2.2. 累加器架构 (Accumluator Architecture)下面是一个累加器的结构。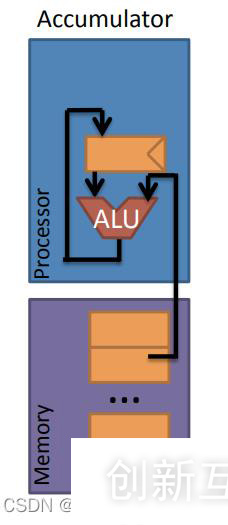
累加器,顾名思义会对一个数值不停的做加法,而得到的结果最终也只会有一个,操作数只有一个,因此在处理器中只会有一个寄存器,所有的计算都是自动的或不可见的。同时还可以提供给累加器另外一个操作数,即除了寄存器中的操作数还提供一个来自存储器 (Memory) 的操作数,此时则需要给该操作数命名。
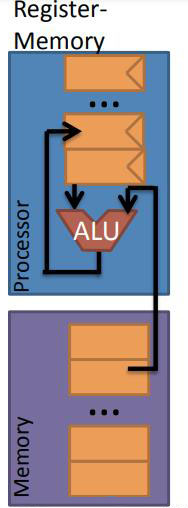
根据上面累加器的两个参数方案那么很容易想到上图这种架构,寄存器-存储器架构,即一个源操作数来自于存储器,该操作数需要命名,而另一个操作数可以来自于寄存器(不需要命名),然后,还可以有一个目的存储(可选),用于保存计算结果的存储位置,同样需要命名才可以。那么这种结构一个操作最多需要有两个命名的操作数。
2.4. 寄存器-寄存器架构 (Register-Register Architecture)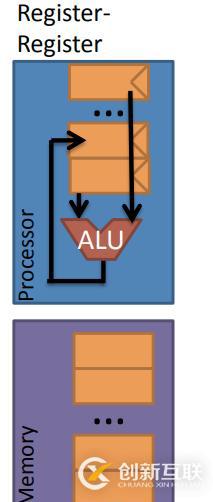
那么寄存器-寄存器架构,两个操作数均来自于处理器中的寄存器,同时两者均需被命名,当需要有目的存储时,还需要为目的存储操作数命名。
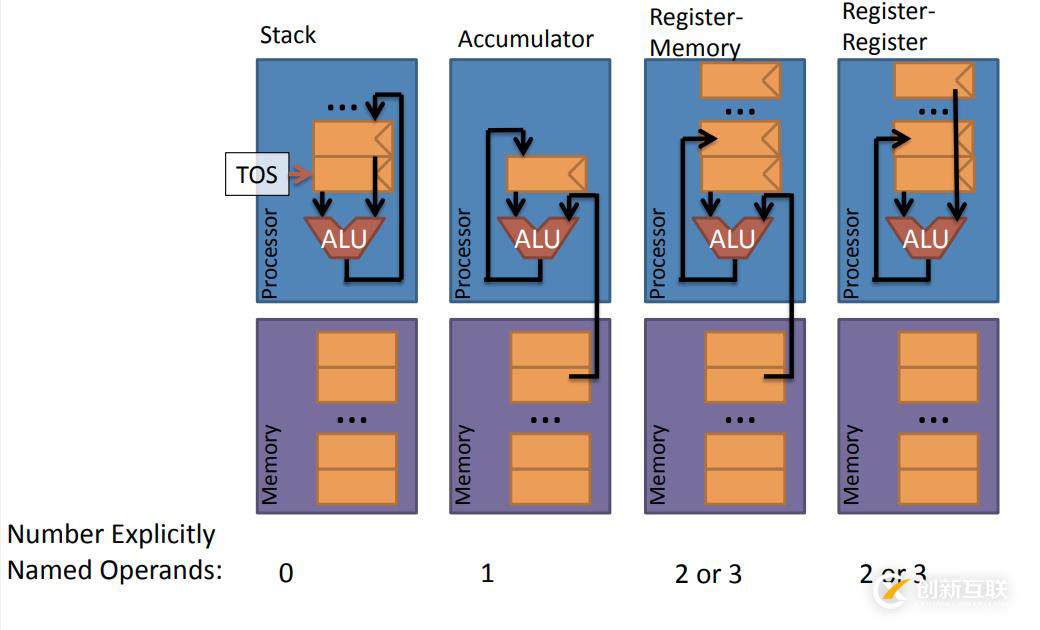
这四种架构,需要被命名的操作数数目分别为0、1、2或3、2或3,相信通过上文你已经清楚了,后面两种架构为什么是2或3,因为有时候数据计算结果的保存目的地会隐式的确定无需命名,当需要明确指出时,那么就会多一个命名操作数。
例如,X86架构中的第一个操作数总是作为结果的保存位置,因此它会少命名一个操作数。例如MIPS、RISC架构则需要将三个操作数全部命名。
栈基架构虽然是个很老的架构模型,但是很经典。过去的Burrough's 5000 (B5000)机器就是使用的栈基架构(1960年),近一点的Java虚拟机实际上也是利用栈结构实现。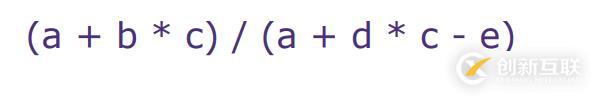
用一个例子🌰来说明栈基架构机器模型的工作原理,来看上图这个计算表达式,首先用a加上b * c,然后整个括号的计算结果除以a加上d * c再减去e的运算结果才得到最终的表达式结果。这对于我们来说计算这个表达式很简单,但对于计算机来说就没那么直接了,甚至有点复杂。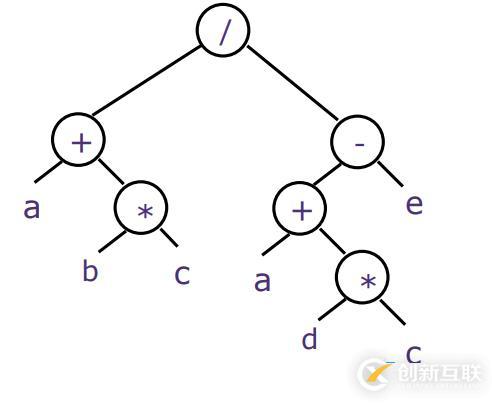
实际上计算机会将这个表达式分解并生成一个 解析树,就上图这样。一个二叉树的结构,所有的叶子节点上是需要做计算的数,其它节点则是运算符。开始先由b乘以c加上a,用这个结果除以另一边的子表达式。整个二叉树用顺序结构保存即为计算机应该要做的操作表达式,像下面这样。

如果现在使用的是栈基架构的机器模型,那么就意味着会有一个求值栈,首先pusha到栈中,接着push b到栈中、push c到栈中,当遇到运算符,拿栈顶的两个元素做对应的运算,再保存到栈中,依次类推就会得到下面这样的栈操作流程。
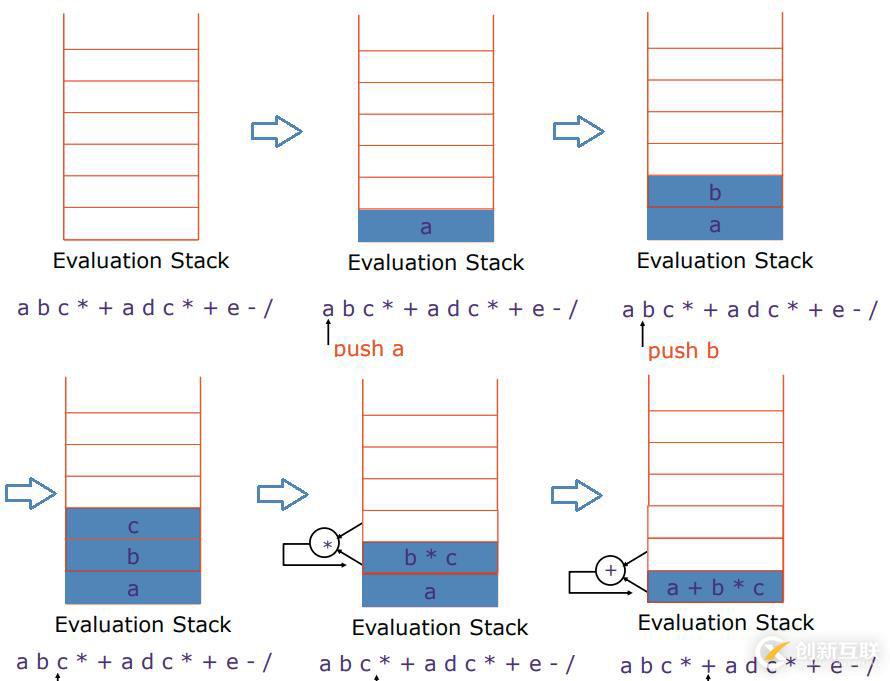
通过这样的栈操作流程,就可以把左边的子表达式结果计算出来,依照该方法继续姐可以计算出整个表达式的结果。你会发现计算机在计算这样长的表达式,实际上可以在一个很小的栈中完成对整个表达式的计算,并且有一个好处是,完全不需要对任何一个操作数命名(因为操作数是固定的,总是拿栈顶的两个元素作运算)。因此这个机器模型可以让你跑任何现实的程序。
⭐
需要注意的一点是,栈是处理器状态的一部分,并且很多时候在指令集体系架构的角度来看栈是无限大的。但在实际上,计算机中的栈是有限长的,因为在计算机中无论如何都不可能出现一个无限长且真实存在的栈。它只是在概念上是无限的,因此你需要保证不能发生栈溢出(内存溢出、主存储器溢出)。 例如,上面例子中的表达式如果是很长,或者产生的解析树太深,都会导致栈溢出的可能。
🤕基础设计:
假如现在有一个指令集架构的微架构实现是基于栈基架构的,由于求值栈在进行计算时总是需要两个操作数,那么就将求值栈中的顶部的两个元素的地址是保存在寄存器中,而其余的则保存在主存中(包含溢出的元素)。每一次入栈操作都会产生一次内存引用,每一次出栈操作也会有一次内存引用(出栈会将栈中的元素返回到主存中)。而且更重要的是,当发生栈溢出后,将会增加额外的内存引用,因为在做栈操作时需要将主存的数据先拿出来。显然,这样的结构让操作产生的步骤非常的多(内存引用)。
🤪优化设计:
那么站在微系体系架构优化的角度考虑,将栈中的N个元素全部直接保存在寄存器中(栈中的所有元素N小于或等于可用的寄存器数),这样每次执行push和pop操作时就不必执行内存引用,就只有当发生栈溢出时才需要增加一步内存引用操作。
Okay,用优化后的栈来计算一下,继续再用上面的例子,现在给出限制条件,限制栈的大小为 2,即最多只能放两个元素,超过则会发生溢出。

先来看这个例子都会做什么,首先push了三次元素进栈,然后对顶部的两个元素做乘法,然后再做加法,之后再三次push操作,栈顶两个元素相乘,用结果加上a,接着push e,用上一次结果减去e,再将栈顶两个元素做除法完成计算。
但是栈中只能存放两个元素,那么来看看在栈操作中具体会发生什么事情,
- 第一步
push a,这时候时空栈,没问题,直接进,非空非满栈; - 第二步,接着
push b,也 OK,此时为满栈; - 第三步,当
push c的时候,发现栈已经满了,这个时候还想要再push,那就会发生 栈下溢(Underflow),此时会先将栈底元素也就是a,保存到主存中(Main Memory),该操作会发生一次内存引用,图中的ss(a)表示将astore到主存中,R0寄存器的值改变为a的主存地址(这便发生额外的一次内存引用),然后将c压入栈顶。 - 第四步,将栈顶的两个元素做乘法运算,将结果
b * c保存到R1,栈元素减一,同时从a的主存地址获取(fetche)a(发生内存引用)也就是图中的sf(a),将a保存到R0中,此时栈中有两个元素,栈顶是R1 = b * c,满栈; - 第五步,将栈顶的两个元素做加法运算,将结果
a + b * c入栈保存到R0,栈元素减一,此时栈中只有一个元素即为栈顶元素R0 = a + b * c,非空非满栈; - 第六步,
push a,进栈,没问题,R1 = a,此时为满栈,栈顶元素为a; - 第七步,
push d进栈,发生underflow,将栈底元素保存到主存发生一次内存引用(ss(a + b * c)),R0保存a + b * c的存储地址,此时栈顶元素为R2 = d,满栈; - 第八步,
push c进栈,发生underflow,将栈底元素保存到主存,发生一次内存引用(ss(a)),此时栈顶元素为R3 = c,满栈; - 第九步,将栈顶的两个元素做乘法运算,将结果
d + c保存到R2,栈元素减一,同时从a的主存地址获取(fetche)a(发生内存引用)也就是图中的sf(a),将a保存到R1中,此时栈中有两个元素,栈顶是R2 = b * c,满栈; - 第十步,将栈顶的两个元素做加法运算,将结果
a + d * c保存到R1,栈元素减一,同时从a + b * c的主存地址获取(fetche)a + b * c的值(发生内存引用)也就是图中的sf(a + b * c),将a + b * c保存到R0中,此时栈中有两个元素,栈顶是R1 = a + d * c,满栈; - 第十一步,
push e入栈操作,发生underflow,将栈底元素保存到主存发生一次内存引用(ss(a + b * c)),R0保存a + b * c的存储地址,此时栈顶元素为R2 = e,满栈; - 第十二步,将栈顶的两个元素做减法运算,将计算结果
a + d * c - e保存到R1,栈元素减一,同时从R0保存的主存地址拿出a + b * c的值保存进R0,此时为满栈,栈顶元素R1 = a + d * c - e; - 第十三步,将栈顶的两个元素做除法运算,将计算结果
(a + b * c) / (a + d * c - e)用R0保存,栈元素减一。
统计一下,利用这个求值栈计算过程中间接性的做了4次store操作和4次fetche操作,也就是说使用该结构栈在正常的流程中额外的增加了8次访存操作。
我们改变一下栈大小会发生什么,将栈的大小增加为4,那么它的执行流程将会是下面这样。

哇呜,一气呵成,中间没有发生内存引用,Good。因为计算该表达式最多的情况下会一次性有4个元素在栈中,那么栈的大小只要满足,就不会发生栈溢出的情况,也就不会有内存引用这样额外的访存操作了。
通过上面的几个例子,相信各位已经清楚了栈基架构的机器模型。看起来他们是可以成功的完成计算任务,但是有一个明显的问题不知道机智的你有没有发现。第一步的时候push a,将a入栈,接着后面又有一次push a,push c同样是,我们再做重复多余的工作欸!!栈基机器模型的架构很简单,指令很密集,但这对于机器性能不算是好事,因为使用该模型将意味着要面临多次的重新读取。
如果使用指令集架构,如MIPS,那么将会有32个通用寄存器,可以在任何指令中为任何一个寄存器命名。那么这时候,当你已经load了a、b、c、d、e数值到寄存器空间中一次了,那么之后所有关于这几个数的操作时都无需重新load。事实上这个问题时由指令集解决的,并不是基础机器模型的问题,也不是微架构要解决的问题。
上文已经介绍了这四种机器模型,Stack-Based、Accumulator、Register-Memory、Register-Register。现在用一个简单的计算C = A + B,分别使用这四个机器模型,看看会有什么不同。
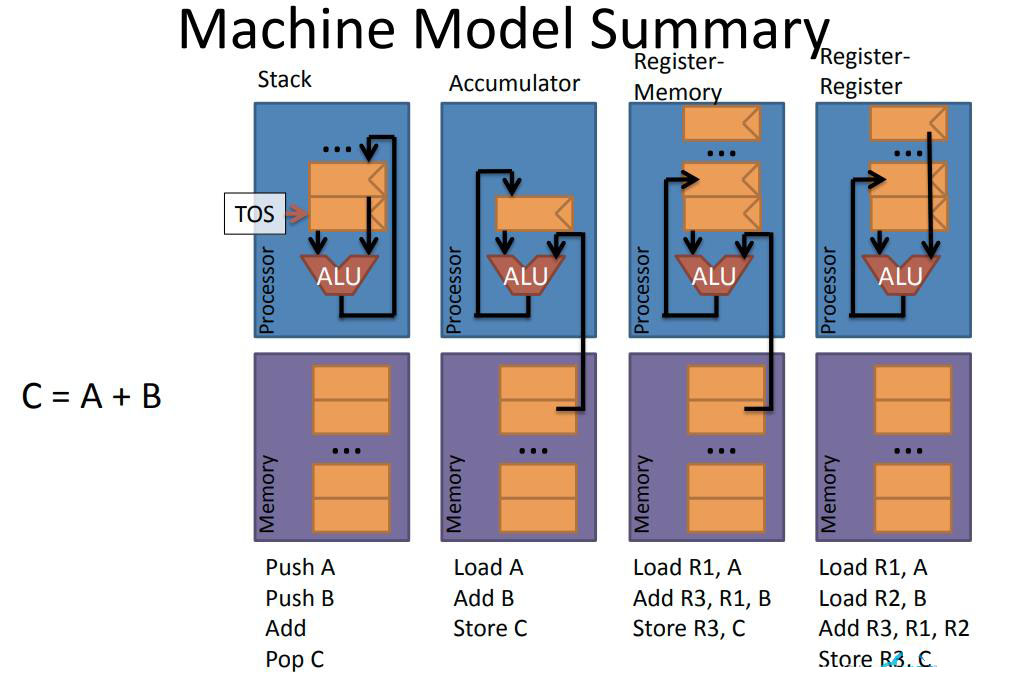
- Stack-Based Architecture
栈基架构的机器模型的工作过程就是,Push A,将A的值入栈,Push B,将B的值入栈,用栈顶两个元素做Add操作,然后将结果Pop到C中保存。
- Accumulator Architecture
累加器的机器模型工作过程为,Load A,Add B即A + B,然后将结果Store到C中。
- Register-Memory Architecture
寄存器-存储器架构机器模型的工作过程,Load R1, A、Add R3, R1, B,将B的值与R1保存的值相加,将结果保存到R3中,再将R3的值Store到C中。
- Register-Register Architecture
寄存器-寄存器架构机器模型的工作过程为,Load R1, A、Load R2, B,执行Add,将R1和R2保存的值相加,并将结果保存到R3中,再将R3的值Store到C中,完成计算。
相比前两个架构,后两个架构在使用A、B之前需要先Load,计算完后还需要Store,看起来似乎不够高效,没有前面两个模型简洁,但是当之后需要重复性的使用A、B的值进行计算的话,那么后两个架构,将不需要再次Load,而可以直接使用,而前两个架构则需要重复性的执行Push或Load指令,这样看起来优势就会体现出来了。
觉得这篇文章对你有帮助的话,就留下一个赞吧*^v^*
请尊重作者,转载还请注明出处!感谢配合~
[作者]: Imagine Miracle
[版权]: 本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
[本文链接]: https://blog.csdn.net/qq_36393978/article/details/128717724
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
分享标题:【计算机体系结构-02】机器模型-创新互联
文章链接:https://www.cdcxhl.com/article0/ceosoo.html
成都网站建设公司_创新互联,为您提供用户体验、移动网站建设、定制开发、企业建站、虚拟主机、做网站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 搜索引擎优化(SEO)主要优化哪几个点? 2016-08-10
- 网站SEO:针对品牌和企业的搜索引擎优化 2022-09-04
- 站外搜索引擎优化战略有哪些 2020-09-18
- 关于搜索引擎优化的误区 2022-06-06
- SEO搜索引擎优化技巧 2015-04-11
- 济宁网站排名有效办理网站搜索引擎优化排名和收录问题,让搜索排名变得垂手可得 2023-01-13
- 门户网站搜索引擎优化的三项讨论 2020-03-31
- 你是否忽略了你的页外搜索引擎优化? 2022-08-19
- 临沂百度快照:「搜索引擎优化平台」天天欣赏的网站是怎么做出来的? 2023-01-04
- 基于Flash的网站的搜索引擎优化技巧 2016-11-16
- 网站建设对搜索引擎优化的重要性 2022-08-27
- 做搜索引擎优化,你不能不知道搜索引擎是如何 2014-02-09